.gif)


分布式锁
为什么需要分布式锁:
在传统单体应用单机部署的情况下,可以使用并发处理相关的功能(如ReentrantLcok或synchronized)进行互斥控制来解决。但是,随着业务的发展,系统架构也会逐步优化升级,原本单体单机部署的系统被演化成分布式集群系统,由于分布式系统多线程、多进程并且分布在多个不同机器上,这将使原单机部署情况下的并发控制锁策略无法满足,并不能提供分布式锁的能力。为了解决这个问题就需要一种跨机器的互斥机制来控制共享资源的访问,这就是分布式所要解决的难题!
分布式锁实现方式:
分布式锁的核心在于将锁的机制与应用程序本身分离。锁必须作为一个公共组件,允许多个应用或多个节点进行访问。通过分布式锁的互斥特性,可以有效解决不同节点对共享资源的竞争访问问题,确保在分布式系统中数据的一致性。因此我们可以选择的方式有:
Redis分布式锁
Zookeeper分布式锁
Mysql分布式锁
一,Redis分布式锁
基于Redis实现分布式锁在日常开发中属于使用最频繁的方式。因此关于Redis实现分布式锁有如下几种可选方案:
setnx + expire
set扩展命令
Redisson开源框架
RedLock(集群模式下的分布式锁)
setnx + expire
setnx命令的意思是,当存入的key不存在时则将命令存入并返回1,当存入的key不存在时则返回0
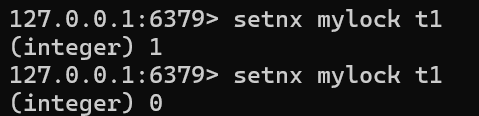
当我们将key存入以后为了避免线程崩溃而锁一直未释放的情况,因此我们需要在setnx后需要对key设置过期时间。
expire mylock总结:这种方式两个步骤不是原子的,因此当在执行第一个命令后线程崩溃则会导致锁无法释放。
set扩展命令
SET key value[EX seconds][NX]这个命令也就是将setnx与expire进行了结合,完善了之前命令不是原子性的缺点。
总结:如果线程设置的时间过短,导致任务未执行完成锁就释放了则会出现一些线程安全问题。
Redisson开源框架
Redisson 是一个用于 Redis 的分布式协调客户端,通常在 Java 项目中使用它来简化对 Redis 的操作。它提供了强大的功能,帮助我们轻松实现分布式锁。
Redisson 实现分布式锁的底层原理是通过一个内部的 "看门狗" 机制,该看门狗会在锁被持有时持续监控锁的状态。在 Redisson 实例被关闭之前,看门狗会自动延长锁的有效期,从而防止锁在执行过程中意外失效。这种机制保证了锁的可靠性和持久性。接下来贴一张流程图。
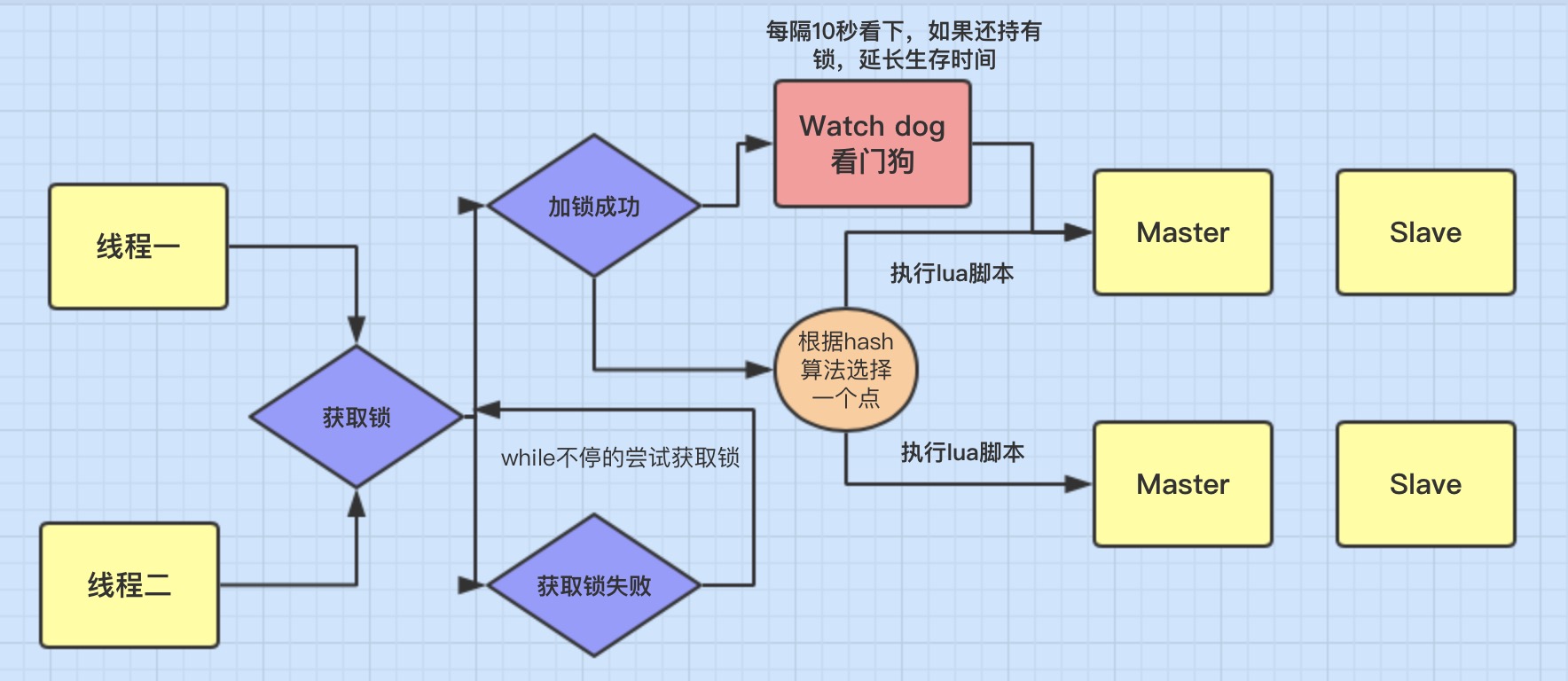
Redisson的可重入是怎么实现的?
使用Redisson的分布式锁时,我们需要设置锁的标识,Redisson会创建一个Hash结构,key为我们自己设置的锁标识,field字段为线程的唯一标识信息,value为重入次数,当进行重入操作时,会先判断field字段是否为当前线程,如果是则value+1,不是则阻塞,当方法执行结束后退出时,他会先将value-1,当value为0时则说明当前线程的锁使用完毕,此时会将key删除。
RedLock
Redis实现分布式锁最简单的方式就是上面所描述的几种方法,但是那些都是针对的单节点。如果面试问到这个问题:如果这个节点挂了怎么办?咱们的回答一定是加机器,让其组成集群,但是组成集群了如果想实现分布式锁该怎么办了呢?
RedLock获取锁过程(5个相互独立的节点):
1. 客户端先获取当前时间戳T1。
2. 客户端依次向5个Redis实例发送获取锁的请求,且每个请求都会设置超时时间(超时时间远远小于锁的过期时间),如果一个Redis实例加锁失败则立刻向下一个客户端加锁
3. 当有大于总节点数的一半(3个节点)节点加锁成功,客户端再次获取时间戳T2,当T2 - T1 < 锁的过期时间则认为加锁成功。此时的有效时间变为了T2 - T1。
4. 当释放锁时需要向所有的节点发送解锁请求。
总结:RedLock解决了单节点的故障问题,但是随之又引来了复杂性的问题,好在Redisson也帮助我们实现了RedLock同时还实现了看门狗机制。
二,Zookeeper分布式锁
Zookeeper 是一个开源的分布式协调服务,支持高性能并发环境,特别适用于分布式应用程序。它提供了四种类型的节点,包括持久节点、持久顺序节点、临时节点和临时顺序节点。借助 Zookeeper 的临时顺序节点特性,可以实现分布式锁。
Zookeeper实现分布式锁的流程:
客户端获取锁时,在lock节点下创建临时顺序节点。
然后获取lock下面所有的子节点,客户端获取到所有的子节点之后,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁。使用完锁后,将该节点删除。
如果发现自己创建的节点并非lock节点下所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件。
如果发现比自己小的那个节点被删除,则客户端的Watcher会受到相应通知,此时再判断自己创建的节点是否是lock子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。
public class Tocket implements Runnable{
private int tickets = 10; // 数据库的票数
private InterProcessMutex lock;
public Tocket(){
CuratorFramework itheima = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(new ExponentialBackoffRetry(3000, 10))
.build();
itheima.start();
lock = new InterProcessMutex(itheima,"/lock");
}
@Override
public void run() {
while (true){
try {
// 获取锁
lock.acquire(1, TimeUnit.SECONDS);
if(tickets > 0){
System.out.println(Thread.currentThread()+":"+tickets);
tickets--;
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
lock.release();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
}
}三,Mysql分布式锁
Mysql想要实现分布式锁其依靠的是其自带的排它锁机制。
select id,lock_key from Table_name where lock_key = 'xxx-lock' for update;
// lock_key 这个字段必须存在索引当执行上述语句时对应的记录会被添加上行锁,这个Record Lock属于写锁会阻塞其他线程的读或写,当其他线程再对相同的记录执行上述语句时就会发生阻塞,由此实现了分布式锁。
如果是Spring项目想利用Mysql实现分布式锁则需要在方法上添加事务注解(@Transaction),因为当任务执行完毕退出时事务会提交这样分布式锁就解除了,其他的线程则可以获取分布式锁。
但是貌似这种方法好像无法做到可重入锁?其实我们可以将锁的获取信息保存到ThreadLocal中,这样在执行可重入操作时先判断ThreadLocal中释放有相应的记录,如果有就不执行语句将ThreadLocal中的value+1,当退出时再将value-1,当value为0则删除对应的标识,防止出现内存泄漏问题。
